ZHANG HAO
ZHANG HAO
Home
Experience
Publications
CV
Light
Dark
Automatic
paper-conference
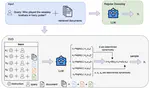
Frame-Voyager: Learning to Query Frames for Video Large Language Models
Video Large Language Models (Video-LLMs) have made remarkable progress in video understanding tasks. However, they are constrained by …
Sicheng Yu
,
Chengkai Jin
,
Huanyu Wang
,
Zhenghao Chen
,
Sheng Jin
,
Zhongrong Zuo
,
Xioalei Xu
,
Zhenbang Sun
,
Bingni Zhang
,
Jiawei Wu
,
Hao Zhang
,
Qianru Sun
Preprint
PDF
Cite
📌ICLR'25
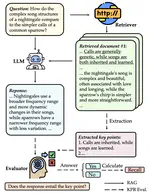
Reverse Modeling in Large Language Models
Humans are accustomed to reading and writing in a forward manner, and this natural bias extends to text understanding in …
Sicheng Yu
,
Yuanchen Xu
,
Cunxiao Du
,
Yanying Zhou
,
Minghui Qiu
,
Qianru Sun
,
Hao Zhang
,
Jiawei Wu
Preprint
PDF
Cite
DOI
📌NAACL'25
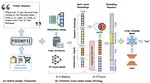
MR-Ben: A Meta-Reasoning Benchmark for Evaluating System-2 Thinking in LLMs
Large language models (LLMs) have shown increasing capability in problem-solving and decision-making, largely based on the step-by-step …
Zhongshen Zeng
,
Yinhong Liu
,
Yingjia Wan
,
Jingyao Li
,
Pengguang Chen
,
Jianbo Dai
,
Yuxuan Yao
,
Rongwu Xu
,
Zehan Qi
,
Wanru Zhao
,
Linling Shen
,
Jianqiao Lu
,
Haochen Tan
,
Yukang Chen
,
Hao Zhang
,
Zhan Shi
,
Bailin Wang
,
Zhijiang Guo
,
Jiaya Jia
Preprint
PDF
Cite
Code
Dataset
Project
Poster
📌NeurIPS'24
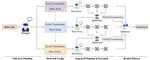
DVD: Dynamic Contrastive Decoding for Knowledge Amplification in Multi-Document Question Answering
Large language models (LLMs) are widely used in question-answering (QA) systems but often generate information with hallucinations. …
Jing Jin
,
Houfeng Wang
,
Hao Zhang
,
Xiaoguang Li
,
Zhijiang Guo
PDF
Cite
Code
DOI
📌EMNLP'24
LONG2RAG: Evaluating Long-Context & Long-Form Retrieval-Augmented Generation with Key Point Recall
Retrieval-augmented generation (RAG) is a promising approach to address the limitations of fixed knowledge in large language models …
Zehan Qi
,
Rongwu Xu
,
Zhijiang Guo
,
Cunxiang Wang
,
Hao Zhang
,
Wei Xu
Preprint
PDF
Cite
Code
DOI
📌EMNLP'24
MC-indexing: Effective Long Document Retrieval via Multi-view Content-aware Indexing
Long document question answering (DocQA) aims to answer questions from long documents over 10k words. They usually contain content …
Kuicai Dong
,
Derrick Goh Xin Deik
,
Yi Quan Lee
,
Hao Zhang
,
Xiangyang Li
,
Cong Zhang
,
Yong Liu
Preprint
PDF
Cite
DOI
📌EMNLP'24
Collaborative Cross-modal Fusion with Large Language Model for Recommendation
Despite the success of conventional collaborative filtering (CF) approaches for recommendation systems, they exhibit limitations in …
Zhongzhou Liu
,
Hao Zhang
,
Kuicai Dong
,
Yuan Fang
Preprint
PDF
Cite
DOI
📌CIKM'24
Retrieval-Oriented Knowledge for Click-Through Rate Prediction
Click-through rate (CTR) prediction plays an important role in personalized recommendations. Recently, sample-level retrieval-based …
Huanshuo Liu
,
Bo Chen
,
Menghui Zhu
,
Jianghao Lin
,
Jiarui Qin
,
Yang Yang
,
Hao Zhang
,
Ruiming Tang
Preprint
PDF
Cite
Code
DOI
📌CIKM'24
Planning with Multi-Constraints via Collaborative Language Agents
The rapid advancement of neural language models has sparked a new surge of intelligent agent research. Unlike traditional agents, large …
Cong Zhang
,
Derrick Goh Xin Deik
,
Dexun Li
,
Hao Zhang
,
Yong Liu
Preprint
PDF
Cite
📌COLING'25
Parameter-Efficient Conversational Recommender System as a Language Processing Task
Conversational recommender systems (CRS) aim to recommend relevant items to users by eliciting user preference through natural language …
Mathieu Ravaut
,
Hao Zhang
,
Lu Xu
,
Aixin Sun
,
Yong Liu
Preprint
PDF
Cite
Code
Poster
Slides
📌EACL'24
«
»
Cite
×