Collaborative Cross-modal Fusion with Large Language Model for Recommendation
Abstract
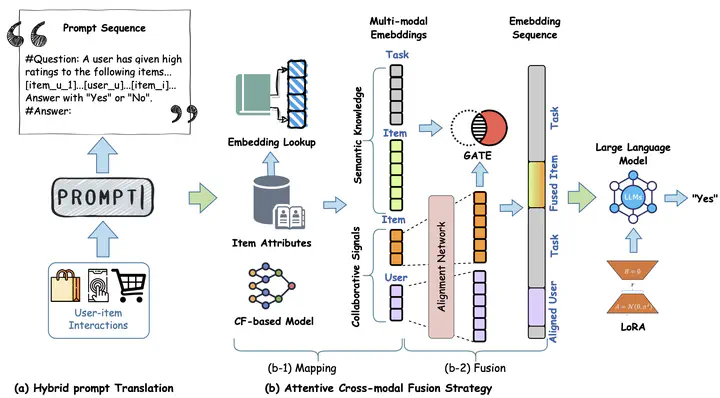
Despite the success of conventional collaborative filtering (CF) approaches for recommendation systems, they exhibit limitations in leveraging semantic knowledge within the textual attributes of users and items. Recent focus on the application of large language models for recommendation (LLM4Rec) has highlighted their capability for effective semantic knowledge capture. However, these methods often overlook the collaborative signals in user behaviors. Some simply instruct-tune a language model, while others directly inject the embeddings of a CF-based model, lacking a synergistic fusion of different modalities. To address these issues, we propose a framework of Collaborative Cross-modal Fusion with Large Language Models, termed CCF-LLM, for recommendation. In this framework, we translate the user-item interactions into a hybrid prompt to encode both semantic knowledge and collaborative signals, and then employ an attentive cross-modal fusion strategy to effectively fuse latent embeddings of both modalities. Extensive experiments demonstrate that CCF-LLM outperforms existing methods by effectively utilizing semantic and collaborative signals in the LLM4Rec context.