Learning Feature Semantic Matching for Spatio-Temporal Video Grounding
Abstract
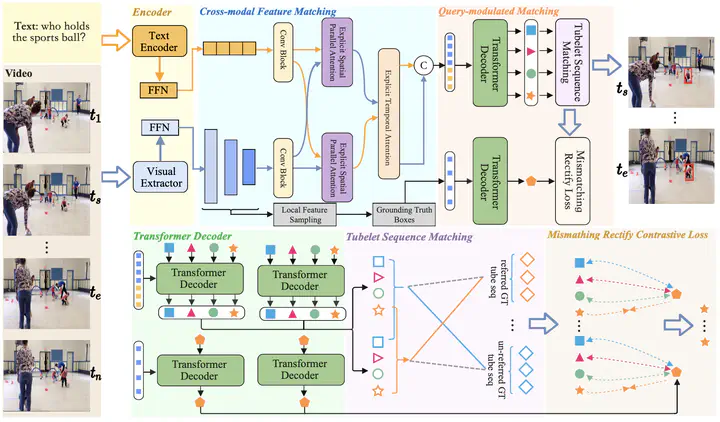
Spatio-temporal video grounding (STVG) aims to localize a spatio-temporal tube, including temporal boundaries and object bounding boxes, that semantically corresponds to a given language description in an untrimmed video. The existing onestage solutions in this task face two significant challenges, namely, vision-text semantic misalignment and spatial mislocalization, which limit their performance in grounding. These two limitations are mainly caused by neglect of fine-grained alignment in crossmodality fusion and the reliance on a text-agnostic query in sequentially spatial localization. To address these issues, we propose an effective model with a newly designed Feature Semantic Matching (FSM) module based on a Transformer architecture to address the above issues. Our method introduces a crossmodal feature matching module to achieve multi-granularity alignment between video and text while preventing the weakening of important features during the feature fusion stage. Additionally, we design a query-modulated matching module to facilitate text-relevant tube construction by multiple query generation and tubulet sequence matching. To ensure the quality of tube construction, we employ a novel mismatching rectify contrastive loss to rectify the mismatching between the learnable query and the objects corresponding to the text descriptions by restricting the generated spatial query. Extensive experiments demonstrate that our method outperforms the state-of-the-art methods on two challenging STVG benchmarks.