How Can Recommender Systems Benefit from Large Language Models: A Survey
Abstract
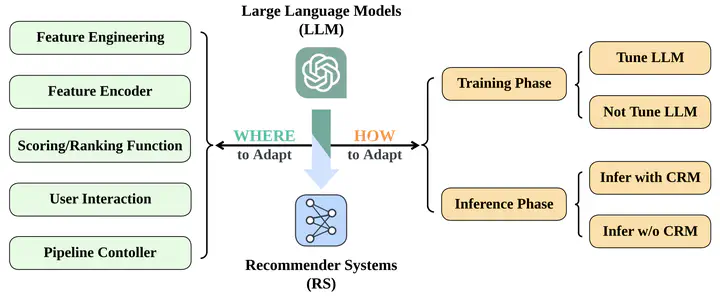
With the rapid development of online services and web applications, recommender systems (RS) have become increasingly indispensable for mitigating information overload and matching users’ information needs by providing personalized suggestions over items. Although the RS research community has made remarkable progress over the past decades, conventional recommendation models (CRM) still have some limitations, e.g., lacking open-domain world knowledge, and difficulties in comprehending users’ underlying preferences and motivations. Meanwhile, large language models (LLM) have shown impressive general intelligence and human-like capabilities for various natural language processing (NLP) tasks, which mainly stem from their extensive open-world knowledge, logical and commonsense reasoning abilities, as well as their comprehension of human culture and society. Consequently, the emergence of LLM is inspiring the design of recommender systems and pointing out a promising research direction, i.e., whether we can incorporate LLM and benefit from their common knowledge and capabilities to compensate for the limitations of CRM. In this paper, we conduct a comprehensive survey on this research direction, and draw a bird’s-eye view from the perspective of the whole pipeline in real-world recommender systems. Specifically, we summarize existing research works from two orthogonal aspects: where and how to adapt LLM to RS. For the WHERE question, we discuss the roles that LLM could play in different stages of the recommendation pipeline, i.e., feature engineering, feature encoder, scoring/ranking function, user interaction, and pipeline controller. For the HOW question, we investigate the training and inference strategies, resulting in two fine-grained taxonomy criteria, i.e., whether to tune LLM or not during training, and whether to involve conventional recommendation models for inference. Detailed analysis and general development paths are provided for both WHERE and HOW questions, respectively. Then, we highlight the key challenges in adapting LLM to RS from three aspects, i.e., efficiency, effectiveness, and ethics. Finally, we summarize the survey and discuss the future prospects. To further facilitate the research community of LLM-enhanced recommender systems, we actively maintain a GitHub repository for papers and other related resources in this rising direction.