MS-DETR: Natural Language Video Localization with Sampling Moment-Moment Interaction
Abstract
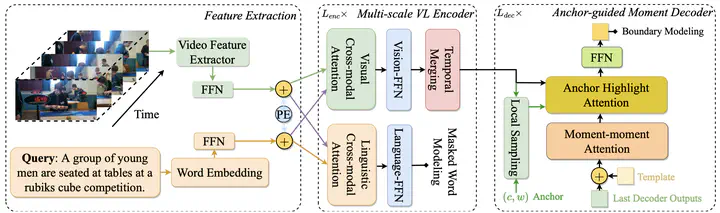
Given a query, the task of Natural Language Video Localization (NLVL) is to localize a temporal moment in an untrimmed video that semantically matches the query. In this paper, we adopt a proposal-based solution that generates proposals (i.e., candidate moments) and then select the best matching proposal. On top of modeling the cross-modal interaction between candidate moments and the query, our proposed Moment Sampling DETR (MS-DETR) enables efficient moment-moment relation modeling. The core idea is to sample a subset of moments guided by the learnable templates with an adopted DETR (DEtection TRansformer) framework. To achieve this, we design a multi-scale visual-linguistic encoder, and an anchor-guided moment decoder paired with a set of learnable templates. Experimental results on three public datasets demonstrate the superior performance of MS-DETR.