Learning to Compress Contexts for Efficient Knowledge-based Visual Question Answering
Abstract
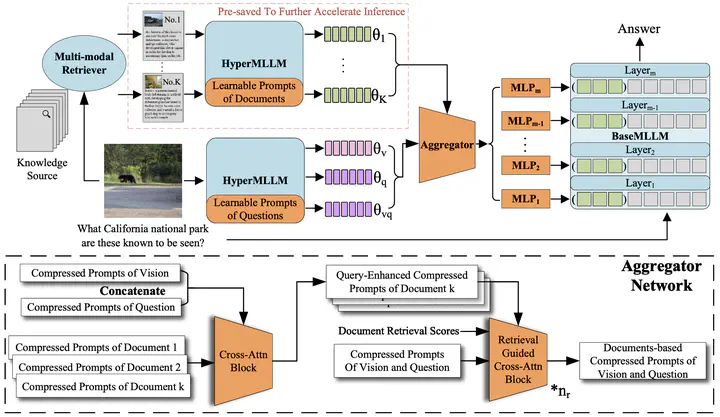
Multimodal Large Language Models (MLLMs) have demonstrated great zero-shot performance on visual question answering (VQA). However, when it comes to knowledge-based VQA (KB-VQA), MLLMs may lack human commonsense or specialized domain knowledge to answer such questions and require obtaining necessary information from external knowledge sources. Previous works like Retrival-Augmented VQA-v2 (RAVQA-v2) focus on utilizing as much input information, such as image-based textual descriptions and retrieved knowledge, as possible to improve performance, but they all overlook the issue that with the number of input tokens increasing, inference efficiency significantly decreases, which contradicts the demands of practical applications. To address this issue, we propose Retrieval-Augmented MLLM with Compressed Contexts (RACC). RACC learns to compress and aggregate retrieved contexts, from which it generates a compact modulation in the form of Key-Value (KV) cache. This modulation is then used to adapt the downstream frozen MLLM, thereby achieving effective and efficient inference. RACC achieves a state-of-the-art (SOTA) performance of 62.9% on OK-VQA. Moreover, it significantly reduces inference latency by 22.0%-59.7% compared to the prominent RAVQA-v2. Abundant experiments show RACC’s broad applicability. It is compatible with various off-the-shelf MLLMs and can also handle different knowledge sources including textual and multimodal documents.