Abstract
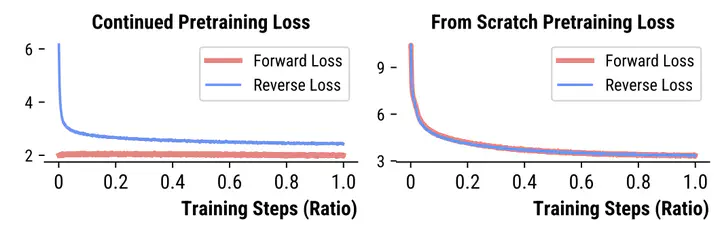
Humans are accustomed to reading and writing in a forward manner, and this natural bias extends to text understanding in auto-regressive large language models (LLMs). This paper investigates whether LLMs, like humans, struggle with reverse modeling, specifically with reversed text inputs. We found that publicly available pre-trained LLMs cannot understand such inputs. However, LLMs trained from scratch with both forward and reverse texts can understand them equally well during inference. Our case study shows that different-content texts result in different losses if input (to LLMs) in different directions – some get lower losses for forward while some for reverse. This leads us to a simple and nice solution for data selection based on the loss differences between forward and reverse directions. Using our selected data in continued pretraining can boost LLMs’ performance by a large margin across different language understanding benchmarks.