Parallel Attention Network with Sequence Matching for Video Grounding
Abstract
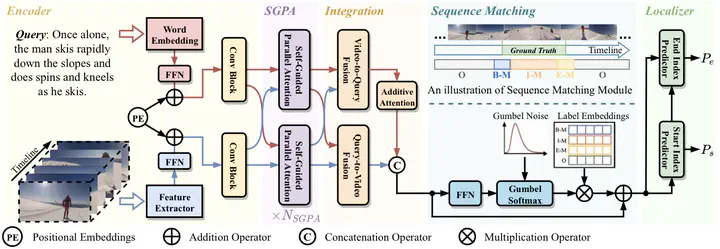
Given a video, video grounding aims to retrieve a temporal moment that semantically corresponds to a language query. In this work, we propose a Parallel Attention Network with Sequence matching (SeqPAN) to address the challenges in this task, multi-modal representation learning, and target moment boundary prediction. We design a self-guided parallel attention module to effectively capture self-modal contexts and cross-modal attentive information between video and text. Inspired by sequence labeling tasks in natural language processing, we split the ground truth moment into begin, inside, and end regions. We then propose a sequence matching strategy to guide start/end boundary predictions using region labels. Experimental results on three datasets show that SeqPAN is superior to state-of-the-art methods. Furthermore, the effectiveness of the self-guided parallel attention module and the sequence matching module is verified.