Temporal Sentence Grounding in Videos: A Survey and Future Directions
Abstract
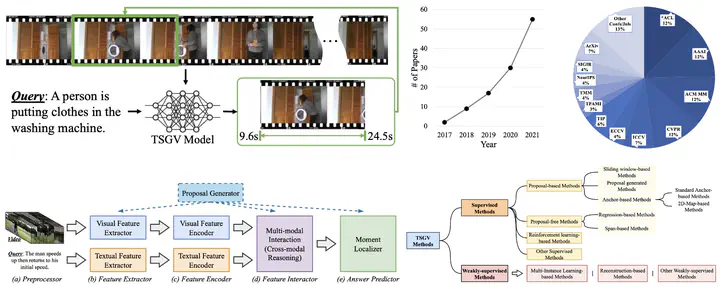
Temporal sentence grounding in videos (TSGV), a.k.a., natural language video localization (NLVL) or video moment retrieval (VMR), aims to retrieve a temporal moment that semantically corresponds to a language query from an untrimmed video. Connecting computer vision and natural language, TSGV has drawn significant attention from researchers in both communities. This survey attempts to provide a summary of fundamental concepts in TSGV and current research status, as well as future research directions. As the background, we present a common structure of functional components in TSGV, in a tutorial style, from feature extraction from raw video and language query, to answer prediction of the target moment. Then we review the techniques for multimodal understanding and interaction, which is the key focus of TSGV for effective alignment between the two modalities. We construct a taxonomy of TSGV techniques and elaborate methods in different categories with their strengths and weaknesses. Lastly, we discuss issues with the current TSGV research and share our insights about promising research directions.