Abstract
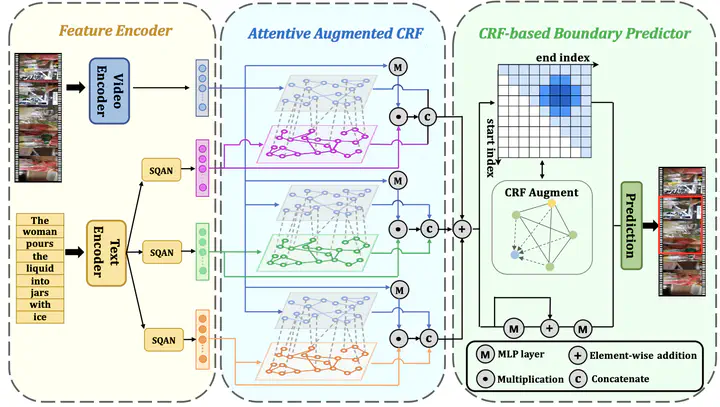
Video Language Grounding is one of the most challenging cross-modal video understanding tasks. This task aims to localize a target moment semantically corresponding to a given language query in an untrimmed video. Many existing VLG methods rely on the proposal-based framework, despite the dominant performance achieved, they usually focus on interacting a few internal frames with the query to score segment proposals, trapping in the long-range dependencies when the proposal feature is limited. Meanwhile, adjacent proposals share similar visual semantics, making VLG models hard to align the accurate semantics of video-query contents and degenerating the ranking performance. To remedy the above limitations, we propose VLG-CRF by introducing the conditional random fields (CRFs) to handle the discrete yet indistinguishable proposals. Specifically, VLG-CRF consists of two cascade CRF-based modules. The AttentiveCRFs is developed for multi-modal feature fusion to better integrate temporal and semantic relation between modalities. We also devise a new variant of ConvCRFs to capture the relation of discrete segments and rectify the predicting scores to make relatively high prediction scores clustered in a range. Experiments on three benchmark datasets, i.e., Charades-STA, ActivityNet-Caption, and TACoS, show the superiority of our method and the state-of-the-art performance is achieved.